
By default, spaCy carries around a powerful battery of pipelines and swings these mighty chainsaws at every passing tree and twig. Sometimes, however, you only want a small pruner to accomplish some smaller task. Can spaCy still work in such a use case? For example, suppose that all I want from spaCy are my documents chunked into sentences.
By default, the spaCy pipeline includes (n.b., this post will focus on English, and details may vary based on selection of languages/models) the following components:
tok2vec: looks up a word vector for each tokentagger: part-of-speech taggerparser: dependency parserattribute_ruler: rule-based token attribute assignment (especially for corrections; see docs)lemmatizer: lookup lemmas (cf. ‘root word’) for wordsner: do named-entity recognition (stored inDoc.ents)
Each of these components depends on certain predecessors, as summarized in the following schematic.
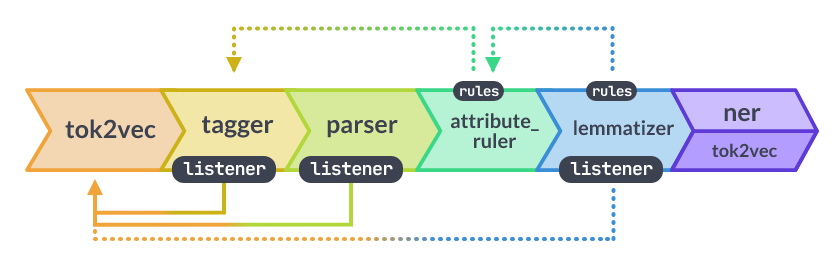
The schematic should be considered guidelines, so individual models or selections (e.g., there are different lemmatizers one might select) might have different sets of dependencies. Perhaps one the simplest ways to figure out what works together is by trial and error (which I’ll show below).
Disabling default modules or enabling non-default modules can usually be completed when loading the model itself. Let’s look at two examples to see the impacts.
nlp1 = spacy.load('en_core_web_sm') # default pipeline
nlp2 = spacy.load('en_core_web_sm', disable=('tagger', 'attribute_ruler', 'lemmatizer', 'ner')) # just keep `tok2vec` and `parser`
# the following is the same as nlp2, but might preferred by enablers
nlp3 = spacy.load('en_core_web_sm', enable=('tok2vec', 'parser'))
# Compare pipeline components
print([x[0]for x in nlp1.pipeline])
# ['tok2vec', 'tagger', 'parser', 'attribute_ruler', 'lemmatizer', 'ner']
print([x[0]for x in nlp2.pipeline])
# ['tok2vec', 'parser']
text = 'Hanna is at the store.'
doc1 = nlp1('Hanna is at the store.')
doc2 = nlp2('Hanna is at the store.')
# Compare entities (`ner`)
print(doc1.ents)
# ('Hanna',)
print(doc2.ents)
# ()
# Compare part-of-speech (`pos`)
print(doc1[0].pos_)
# 'PROPN'
print(doc2[0].pos_)
# ''
Pipelines can also be altered after the model is loaded using the enable_pipe and disable_pipe. The enable_pipe will add that named element to the pipeline while disable_pipe will remove it. (There is also an add_pipe which specializes in adding a pipeline component which is not pre-configured.) In the following snippet, I’ll start with the parser in the pipeline, remove it, and then add it back.
nlp = spacy.load('en_core_web_sm', enable=('tok2vec', 'parser'))
print([x[0]for x in nlp.pipeline])
# ['tok2vec', 'parser']
nlp.disable_pipe('parser') # remove `parser`
print([x[0]for x in nlp.pipeline])
# ['tok2vec']
nlp.enable_pipe('parser') # add `parser` back
print([x[0]for x in nlp.pipeline])
# ['tok2vec', 'parser']
This can be useful in adding your own custom pipelines. Much of this functionality is available from configuration files, but we’ll stick to behavior after launching Python for this post.
Now that we can customize our model pipeline, we can turn to our original quandary: how to use spaCy just to split sentences? There are actually a few different solutions.
First, let’s consider our baseline (nlp1) in which we just follow the default and load all the components. Then, we’ll see how to get sentences for a single piece of text, as well as how we might use it to get sentences.
nlp1 = spacy.load('en_core_web_sm')
# for a single text
sentences = list(nlp1(text).sents)
# across a corpus, where `corpus_iter` is a generator yielding a strings of text
sentences = []
for doc in nlp1.pipe(corpus_iter()):
for sentence in doc.sents:
sentences.append(sentence)
But wait, do we need all the components? We need to identify which component is responsible for doing sentence segmentation, and then trace through its dependencies. In this case, the guilty component is parser, but parser depends on tok2vec. We can thus keep just the tok2vec and parser components. (While you can technically eliminate tok2vec as well, this has negative effects…)
nlp2 = spacy.load('en_core_web_sm', enable=('tok2vec', 'parser'))
# for a single text
sentences = list(nlp2(text).sents)
# across a corpus, where `corpus_iter` is a generator yielding a strings of text
sentences = []
for doc in nlp2.pipe(corpus_iter()):
for sentence in doc.sents:
sentences.append(sentence)
nlp2 will have exactly the same results as nlp1, though without having to run several of the components, thereby saving some processing time.
A third approach is to use the senter component alone. This is effective if you don’t need the dependency parse (i.e., the parser component) since we can use senter alone. (The sentencizer component will also work, but senter is more accurate than sentencizer.)
For the moment, adding senter directly to the enable parameter list won’t work (see this issue), so we’ll need to use our knowledge of enable_pipe to add it.
nlp3 = spacy.load('en_core_web_sm', enable=('tok2vec',))
nlp3.disable_pipe('tok2vec') # not actually required, but easier than disabling everything
nlp3.enable_pipe('senter')
# for a single text
sentences = list(nlp3(text).sents)
# across a corpus, where `corpus_iter` is a generator yielding a strings of text
sentences = []
for doc in nlp3.pipe(corpus_iter()):
for sentence in doc.sents:
sentences.append(sentence)
len(sentences), sentences
This third method will not behave as the previous 2 did since it relies on a different sentence-splitting algorithm.
Does the third method actually take less time? It might be worth experimenting on a subset of your own data. For me, using a random set of 5000 records (on a crappy laptop), got these results using timeit:
# function
def ssplit(nlp):
for doc in nlp.pipe(corpus_iter()):
len(list(doc.sents))
ssplit(nlp1)
# 6min 28s ± 3.71 s per loop (mean ± std. dev. of 2 runs, 1 loop each)
ssplit(nlp2)
# 2min 55s ± 5.46 s per loop (mean ± std. dev. of 2 runs, 1 loop each)
ssplit(nlp3)
# 31.4 s ± 1.18 s per loop (mean ± std. dev. of 2 runs, 1 loop each)
ssplit(nlp4) # nlp3 without disabling `tok2vec`
# 2min 34s ± 2.88 s per loop (mean ± std. dev. of 2 runs, 1 loop each)
So it does appear to speed things up considerably. Note that it is important to use nlp.pipe to avoid reloading components.