
An email arrives with an attached PDF and a request that some multi-page embedded table be extracted into Excel. For example, the following presents a short snippet:
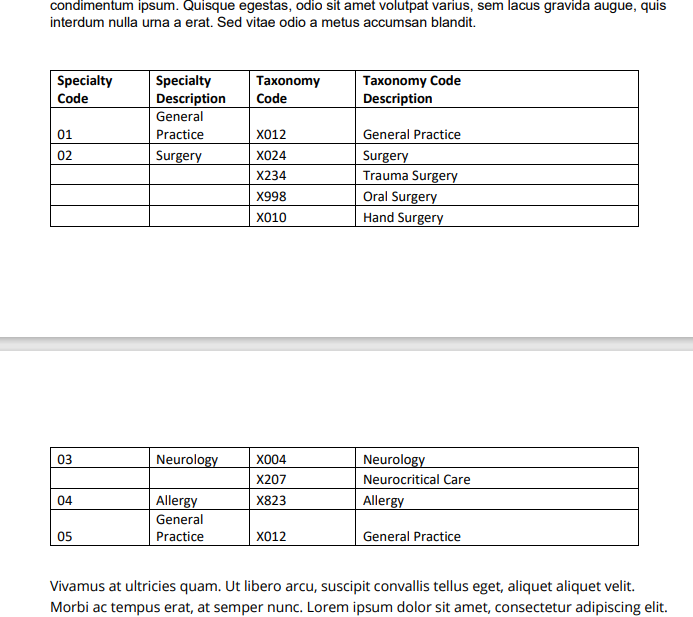
How would you handle it? Sure, this table is relatively trivial to manually extract, but imagine a PDF continuing for several pages.
Fortunately, there are several Python libraries which provide a simple interface. In the previous post, I introduced camelot, and in this, I’ll present with tabula.
Tabula
tabula-py is a project which provides a thin Python wrapper around tabula-java. Like with camelot, the tables are extracted and used to populate a pandas DataFrame.
Installation (on Window)
Since the project is using a Java library, you’ll need Java installed (8+). It should also be placed onto your path so that tabula-py can find it (this should be done by default during the installation process). To test whether or not you have Java installed (and accessible to Python), open a shell and type java -version. If the command isn’t recognized, you’ll need to install Java.
Next, install tabula-py and ensure that you have pandas and xlsxwriter as well:
pip install tabula-py pandas xlsxwriter
Usage
Here’s an example extracting our PDF from above into an Excel document.
# import function from library
from tabula import read_pdf
dfs = read_pdf('mypdf.pdf', pages='all')
type(dfs) # this is just a list
len(dfs) # n=3!
tabula returns a list of DataFrames. We ended up with three tables, when two would have been expected (the first at the bottom of page 1, the second at the bottom of page 2). Let’s see why that happened.
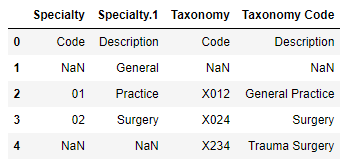
dfs[0].head(). Note that the first row is actually part of the header.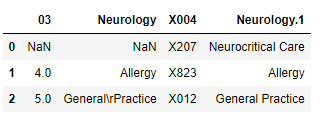
dfs[1].head(). Note the table header is actually a row of data.
dfs[2].head() which shows that some lorem ipsum text was interpreted as a table. We should remove that.Unlike with camelot, this will require a bit more cleaning.
First, let’s dump the last DataFrame:
dfs = dfs[:2] # remove the lorem ipsum DataFrame
Second, let’s get the actual header column.
# get the actual column names, and remove any extraneous numbers pandas inserted into duplicate column names
header1 = [c.split('.')[0].strip() for c in dfs[0].columns]
# separate the second part of the headers from the actual rows of data
header2, *rows = dfs[0].to_numpy()
# generate a new header by combining `header1` and `header2` values
new_header = [f'{h1} {h2.strip()}' for h1, h2 in zip(header1, header2)]
print(new_header)
##> ['Specialty Code',
'Specialty Description',
'Taxonomy Code',
'Taxonomy Code Description']
Third, we can build the final DataFrame:
for df in dfs[1:]: # make extensible since there could be more tables
# add column header (which is actually a row of data) to the rows
rows = np.vstack([rows, [np.array(df.columns)]])
# add the data rows to the previous rows
rows = np.vstack([rows, df.to_numpy()])
From this, we can create our pandas DataFrame:
df = pd.DataFrame(rows, columns=new_header)
print(df)
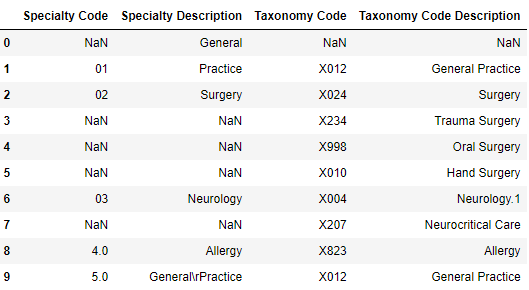
We’re close, but it will require a little manual clean-up (e.g., index-0 and index-1 need to be merged). Still, we extracted data relatively painlessly.
Now, to Excel:
# just our final dataframe
df.to_excel('table.xlsx')
# all of our tables
with pd.ExcelWriter('tables_in_parts.xlsx', engine='xlsxwriter') as writer:
for i, df in enumerate(dfs):
df.to_excel(writer, sheet_name=f'part_{i}')
Parting Thoughts
tabula is quite powerful, though camelot did a lot better with this output, and it’s also (apparently) more extensible by enable additional configurations and supporting excalibur.