
An email arrives with an attached PDF and a request that some multi-page embedded table be extracted into Excel. For example, the following presents a short snippet:
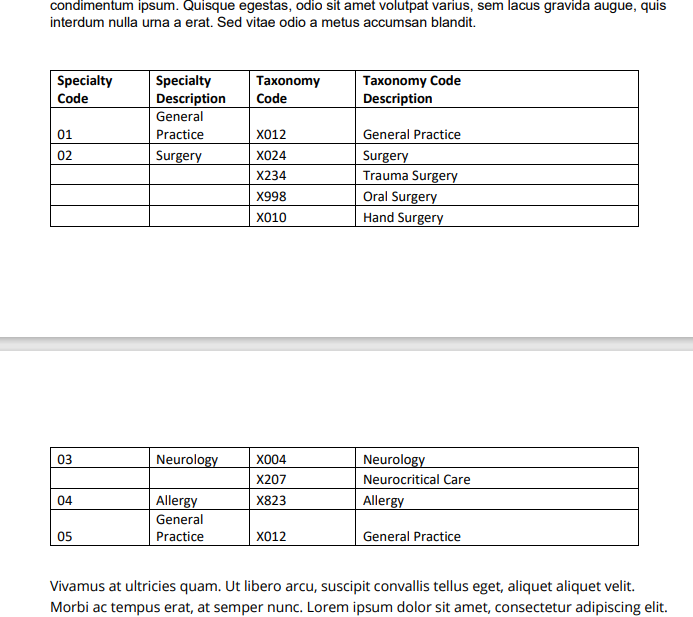
How would you handle it? Sure, this table is relatively trivial to manually extract, but imagine a PDF continuing for several pages.
Fortunately, there are several Python libraries which provide a simple interface. In this post, I’ll present Camelot, and in the next I’ll describe tabula.
Camelot
Camelot was created to aid in the admittedly crowded market of PDF table extractors by allowing more fine-grained configurations. In fact, the project also provides a GUI interface called excalibur. Both projects are looking for maintainers and contributors, so if this excites you, please take a look there!
Installation on Window
First, you’ll need Ghostscript which can be obtained from: Ghostscript : Downloads. Download and install the executable. The default install location is fine: somewhere around C:\Program Files\gs\gs10.01.2\ (with your precise version information). Next, add the bin\ subdirectory to your PATH environment variable: C:\Program Files\gs\gs10.01.2\bin. (Alternatively, you can add it to the top of your script, see below.)
Second, to get the library in its current state requires a little extra work on the command line (in the future, it should be quite simply pip install camelot-py). At the time of writing:
pip install camelot-py[base] opencv-python-headless 'PyPDF2<3.0'
Usage
Here’s an example extracting tables to Excel. First, remember that Ghostscript must be on your path, otherwise you can add it using the os module.
# if you didn't add to your path
import os
os.environ['PATH'] = r'C:\Program Files\gs\gs10.01.2\bin;' + os.environ['PATH']
Next, we’ll load the camelot library and read the PDF. This is where the magic happens:
import camelot
pdf = camelot.read_pdf('mypdf.pdf', pages='all') # read 'all' pages, otherwise defaults to just the first
print(pdf)
##> <TableList n=2>
Logging output is quite robust and will provide warnings if, e.g., a page doesn’t have a table on it. The output is a list of pandas dataframes for each table. The n=2 shows that it found two. We only have a single table, but since they appear on different pages, the ‘first’ appears at the end of page 1, and the ‘second’ appears at the beginning of page 2.
We can peak into the tables, and perhaps consider concatenating them within Python:
len(pdf) # number of tables
pdf[0] # access the first table
pdf[1].df # get the pandas dataframe for the second table
for table in pdf: # can iterate through tables
print(table.df.head())
Inspecting the tables, it looks like we can easily concatenate them and then set the first row to be the header.
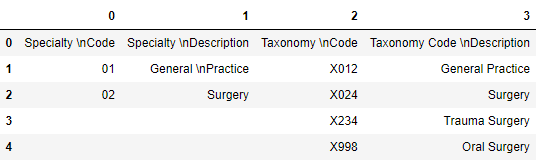
pdf[0].df.head().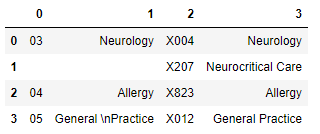
pdf[1].df.head().To concatenate and output to excel:
import pandas as pd
# stack all of the tables into a single dataframe
df = pd.concat([table.df for table in pdf])
# convert to numpy arrays to take out the first row to use as column header
header, *rest = df.to_numpy()
# create our new output dataframe
df = pd.DataFrame(rest, columns=header)
# write to excel (may need to `pip install xlsxwriter`)
df.to_excel('tables.xlsx')
If the tables didn’t line up so well, you can also export them all independently and stitch them together manually (or, if the header row is causing problems which it often does, concat rows 2-n, and then manually fix the header).
# write table from each page into Excel document
with pd.ExcelWriter('tables_in_parts.xlsx', engine='xlsxwriter') as writer:
for i, table in enumerate(pdf):
table.df.to_excel(writer, sheet_name=f'part_{i}')
# write first table, and then the rest concatenated
with pd.ExcelWriter('tables_2.xlsx', engine='xlsxwriter') as writer:
pdf[0].df.to_excel(writer, sheet_name='first')
pd.concat([table.df for table in pdf]).to_excel(writer, sheet_name='rest')
Parting Thoughts
camelot was quite impressive, and the demos I’ve seen of excalibur blow me away. I also appreciate that it doesn’t put anything into the column headers which pandas requires to be unique. When using tabula this requires quite a few additional steps of clean-up.