
In natural language processing tasks (especially when building regular expression-based tools), it’s important to be able to review text efficiently. When I first started, the default approach was reviewing in an Excel workbook. This involved a few columns of metadata, a giant blurb of text to be reviewed, followed by a column to record the abstraction classification(s).
This approach followed a typical pipeline whereby the data side dominated — this was the easiest format to generate. I’ve used this a few a times, though I’d usually reduce the size of the text blob and add highlighting to the keyword (or keywords) which the abstraction expert was looking for. I’ve also built a number of chart abstraction instruments that have faciliatated the rapid review of text, focusing on review of small snippets and using highlighting to focus attention on key aspects.
The most pervasive and easy to share tool, however, remains Excel. This is a format that is easily comprehensible, available to all individuals with access to the file, and doesn’t have any learning curve. Therefore, finding an approach to enabling chart abstraction using Excel is important for many projects.
The method we’ve largely relied upon has been, essentially, keyword or pattern validation. The idea is that we want to look for certain keywords, expressions, etc. in text. We can locate these using regular expressions and designing these regular expressions to be as generous or lenient as possible. In other words, we want to reduce the likelihood of missing anything and ensure that everything that might possibly be relevant gets reviewed by an abstraction expert.
To focus the review on this term or phrase, we’ll use three columns. The second column (centered) will contain the matched text — i.e., the text that the pattern identified. The first column will contain the ‘pre-context’ window (i.e., the ~100 characters before the start of the pattern), and the third column with contain the ‘post-context’ window (i.e., the ~100 characters after the end of the pattern). The actual context windows can vary depending on the actual application — sometimes they need to be a bit longer, othertimes a bit shorter. A fourth column might include the entire precontext (no character limitation) and a fifth the entire postcontext. Thus, if the reviewer needs to peak a bitter further forward or backwards, they are able to do just that.
Thus, the Excel table might look something like this:
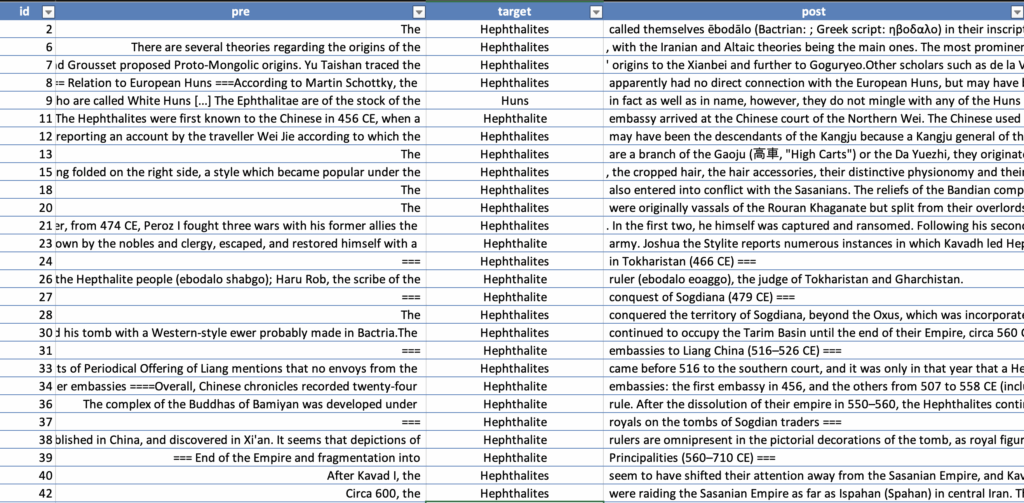
You can see how much more quickly one could review these records — looking at the keyword(s) in the center, and seeing just enough context to make sense of the term or phrase. (In the above, we grabbed an article about the Hephthalites from Wikipedia).
Figuring out an efficient way to build this in Excel is important. Since adopting polars (over pandas), I’ve had to find new approaches to doing things like this. Here’s my approach.
First, let’s get some random Wikipedia data to play with:
import json
import requests
r = requests.get(
f'https://en.wikipedia.org/w/api.php?action=query&prop=extracts&explaintext=1&redirects=1&titles=Hephthalites&format=json'
)
r.raise_for_status()
text = next(iter(json.loads(r.text)['query']['pages'].values()))['extract']
# make multiple records when a section is divided by >= 2 newlines
lst = re.split('\n{2,}', text)
with open('hephthalites.jsonl', 'w') as out:
for i, el in enumerate(lst):
out.write(json.dumps({
'id': i,
'text': el,
}) + '\n')Okay, now we have a corpus of notes about the Hephthalites. Let’s use polars to read this corpus and review mentions of ‘Hephthalites’ or ‘Huns’ (the Hephthalites are also referred to as the ‘White Huns’). We’ll search for hephthalite(s) or hun(s) using a regular expression specified by target.
import polars
import re
# n.b., for the Excel writing to work, we'll need to also install xlsxwriter
df = pl.read_ndjson('hephthalites.jsonl')
target = r'\b(?:hephthalites?|huns?)\b'
# this pattern will grab the target and 100 characters before and after
pattern = fr'(?P<pre>.{{0,100}})(?P<target>{target})(?P<post>.{{0,100}})'We now have our pattern ready and our corpus loaded into a dataframe:
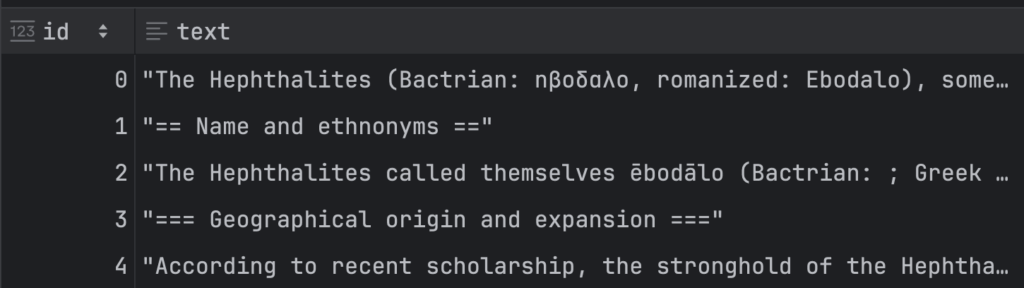
You can see we haven’t done a great job of chunking our text, but we’ll ignore that for now…our goal is just to use this dataset to explore building an abstraction tool. To explore our various options, let’s suppose we only want to review ‘notes’ where our target pattern appears, but not any in which ‘Alchon Huns’ appears (another Hunnic tribe). To do this, we’ll first filter on only notes containing our pattern, and not containing the ‘Alchon Huns’:
df.filter(
pl.col('text').str.contains(fr'(?is){pattern}'),
~pl.col('text').str.contains(fr'(?is)alchon\W*{pattern}'),
)The str.contains will treat the pattern as a regular expression. We’ve specified regex flags i (lowercase) and s (dot matches all) — not relevant here, but can help if your pattern wants to allow arbitrary characters and the match might span a couple lines. The first filter limits to only notes with our pattern, and the second removes any notes containing a mention of the ‘Alchon Huns’.
Next, we need to actually search with our pattern and extract the groups into separate columns:
df.filter(
pl.col('text').str.contains(fr'(?is){pattern}'),
~pl.col('text').str.contains(fr'(?is)alchon\W*{pattern}'),
).with_columns(
pl.col('text').str.extract_groups(pattern).alias('ctxt')
).unnest('ctxt')[['id', 'pre', 'target', 'post']]This will give us a combined column (ctxt) which we’ll unnest and then select only those columns we care about. If we want to move this into Excel, we’ll just write to excel using write_excel:
df.filter(
pl.col('text').str.contains(fr'(?is){pattern}'),
~pl.col('text').str.contains(fr'(?is)alchon\W*{pattern}'),
).with_columns(
pl.col('text').str.extract_groups(pattern).alias('ctxt')
).unnest('ctxt')[['id', 'pre', 'target', 'post']].write_excel('hephthalites.xlsx')While this approach doesn’t fit all types of reviews, it can make labeling activites both easier and more efficient.