
The basic need I have is to convert the codes in a MEDDRA dataset to CUIs (UMLS concept unique identifiers). If there were only 10 or so, I’d look them up on the Metathesaurus manually…but I have a dataset of 155 related to COVID-19. Once I have the CUIs, I can limit the output from Metamaplite to only those with relevant COVID-19 CUIs.
To do this programmatically, I am planning to use httpie to fire the relevant curl commands from the documentation. Well, the documentation looks a bit sparse, but I think I can make it work.
- Connect to Metathesaurus home page and login. (If you don’t have an account, you need to sign up first…)
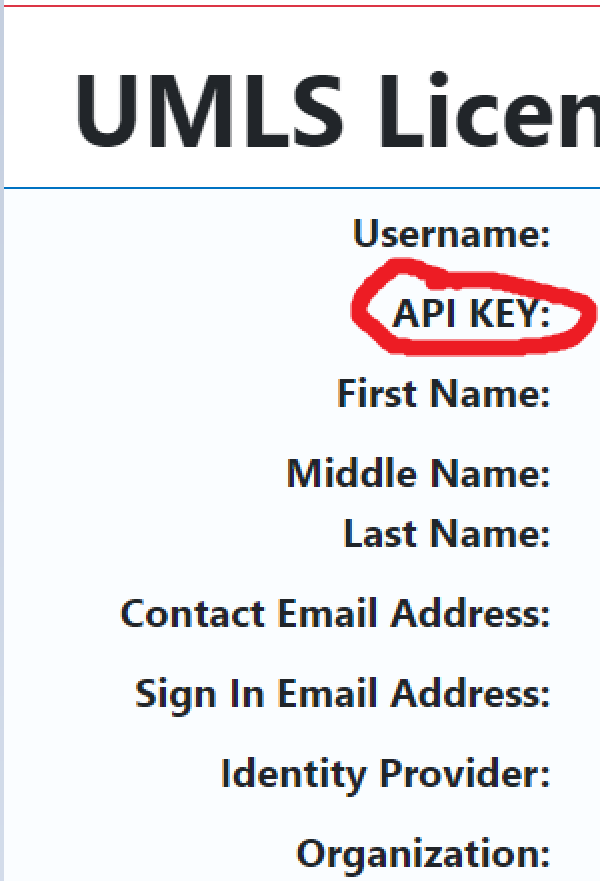
- To obtain the API KEY for your account, choose “My Profile”. (This can be reset going to “Edit Profile” at the bottom of the page.

3. After activating a new virtual environment and installing httpie, I ran this command:
http --form POST https://utslogin.nlm.nih.gov/cas/v1/api-key apikey={INSERT_API_KEY_VALUE_HERE}
The response includes the TGT key (begins with TGT, ends with cas.

This is my ‘TGT’, which I should generate for each session. I then use the TGT to generate an individual ‘ST’ or ticket. It would be rather time-consuming and error prone to continue using httpie in this context, so let’s write a short script.
In a config.py, I’ll place my API_KEY and the LIST of target Meddra codes I’m interested in. I’ll also store the VERSION (setting to ‘current‘ which is the most recent UMLS version). A future refactoring should load these from the command line.
Then, we can create a main.py which I’ve based on some sample code provided by HHS (that code isn’t great — a pull request or two would be good — but it points you in the right direction).
import requests
import json
from config import API_KEY, VERSION, LIST
from lxml.html import fromstring
def get_tgt():
"""Retrieve session-based token"""
r = requests.post(
f'https://utslogin.nlm.nih.gov/cas/v1/api-key',
data={'apikey': API_KEY},
headers={'Content-type': 'application/x-www-form-urlencoded', 'Accept': 'text/plain', 'User-Agent': 'python'},
)
return fromstring(r.text).xpath('//form/@action')[0]
def get_ticket(tgt):
"""Retrieve request-based token"""
r = requests.post(
tgt,
data={'service': 'http://umlsks.nlm.nih.gov'},
headers={'Content-type': 'application/x-www-form-urlencoded', 'Accept': 'text/plain', 'User-Agent': 'python'},
)
return r.text
if __name__ == '__main__':
tgt = get_tgt()
cuis = []
for string in LIST:
ticket = get_ticket(tgt)
# NB: 'exact' must be used when searching for 'code'
r = requests.get(
f'https://uts-ws.nlm.nih.gov/rest/search/{VERSION}',
params={'string': string, 'ticket': ticket, 'inputType': 'code', 'searchType': 'exact'},
)
r.encoding = 'utf-8'
json_data = json.loads(r.text)
for result in json_data['result']['results']:
cuis.append(result['ui'])
print(cuis)
Here are a couple codes you can try out (the full list I’m using is in the spreadsheet here):
LIST = [
10084510,
10084459,
10084467,
10084382,
}
The output I get is the desired list of UMLS CUIs: ['C0206750', 'C5244047', 'C5244047', 'C5203670', 'C5203670', ...].
Now, I can use the list to select the text mentions of interest, and also package this up for future use.